Info
Check out the original post here.
The recent public release of ChatGPT has taken the internet by storm, sparking conversation about the seemingly limitless possibilities and implications of foundation models. If you’ve tried out the public research preview, you may have noticed that the model occasionally produces convincing but non-factual text. These are called stochastic hallucinations, and are an inherent limitation of this technology in its current form. To learn about this issue and how it can be addressed via grounding, I decided to play around with OpenAI’s API and build a simple chatbot utilizing Retrieval-Augmented Generation (RAG) which you can teach any domain-specific knowledge. Before diving into specifics, let’s first understand what the key principles behind this technology are.
What Is ChatGPT and How Does It Work?
ChatGPT is a natural language processing technology developed by OpenAI. It leverages pre-trained foundation models such as GPT-3 to generate natural language responses to user’s questions. At its core, a GPT model simply performs next-token prediction, determining the most probable next word in a piece of text. For instance, given the sequence of words “The quick brown fox jumps over the lazy”, the model predicts the next word in the sequence to be “dog”, with 99% accuracy. Note that in the image below, the predicted words are highlighted, with their color corresponding to how confident the model is of that prediction.

Simple example of a text completion by "text-davinci-003".
The model’s ability to do this stems from being trained on a massive dataset, containing text from many sources including the internet. As it turns out, there is enough information in this dataset that the model is able to answer simple questions quite easily, if it is encouraged to do so. I use the word encouraged because most of the time, you need to provide a prompt that guides the model to the specific output you want. For example, if I want to know what the capital of France is, one way to do this would be to provide the model with the beginning of a sentence where the answer is likely to appear. Here, the model is given “The capital of France is”, and correctly predicts the next word in the sequence to be “Paris” with a high accuracy.

Simple example of a text completion by "text-davinci-003".
You can even simulate a conversation between two people using this model. Providing it with a script-like input such as “Alice: Hi Bob! How are you doing today?”, causes the model to immediately continue the script.
Simple example of a text completion by "text-davinci-003".
Now this is just the tip of the iceberg, but already yields some interesting results. In fact, it turns out that these models are extremely good at following instructions because of their predictive nature. Providing it with “Write a tagline for an ice cream shop” produces the output “Cool down with our delicious treats!”.

Simple example of a text completion by "text-davinci-003".
An interesting thing to notice here is the probability spectrum of the output text, which is indicated by the color of the highlighted words, with green corresponding to a higher probability. Compared to the previous examples, we see that the output here contains more of a mix between high and medium level probabilities. This is a result of the creative nature of the task it has been provided it with, and the fact that there are many possible (and correct) outputs to the prompt text.
These examples were all produced using the “text-davinci-003” model, which is OpenAI’s most capable text completion model from the GPT-3 generation of language models. ChatGPT is a specifically designed variation of this latest generation of models. On top of the original training dataset, it has been further fine-tuned on a large dataset of conversational text, so it is able to generate responses that are more appropriate for use in a chatbot context. ChatGPT is also capable of inserting appropriate context-specific responses in conversations, making it better at maintaining a coherent conversation. I strongly encourage you to read more about the specifics of ChatGPT here.
Limitations and Workarounds
As mentioned earlier, one of the key limitations of the chatbot implementation of large language model (LLM) technology is its inability to consistently produce factually-accurate output. This is partly due to the fact that there is no truth mechanism or real reasoning happening in the model itself. Remember, it is just predicting tokens. However, it can answer basic questions correctly most time, especially if a certain fact is strongly emphasized in its training dataset. For instance, consider the “The capital of France is Paris” example from earlier. This phrase (and similar formulations of the phrase) can be found in numerous wikipedia pages, articles, books, etc. Hence, when reproducing the beginning of a phrase that the model has seen a lot of before, the next word prediction is obvious. On the other hand, if we ask something more specific, or something which requires complex reasoning, the model begins to struggle.
A general solution to this issue is in-context learning through prompt engineering. This is the task of finding appropriate prompts (the text that is provided to the language model) to yield a completion (the output of the model) which is desired. Some key things to keep in mind when designing an appropriate prompt, according to the OpenAI Cookbook, are:
- Give more explicit instructions. For example, if you want the output to be a comma separated list, ask it to return a comma separated list. If you want it to say “I don’t know” when it doesn’t know the answer, tell it ‘Say “I don’t know” if you do not know the answer.’
- Supply examples. If you give the model a complex task, supplying an example along with it can yield better results.
- Ask the model to answer as if it was an expert. Explicitly asking the model to produce high quality output or output as if it was written by an expert can induce the model to give higher quality answers that it thinks an expert would write.
- Prompt the model to write down the series of steps explaining its reasoning. For example, prepend your answer with something like “Let’s think step by step.” Prompting the model to give an explanation of its reasoning before its final answer can increase the likelihood that its final answer is consistent and correct.
Note that prompt engineering can be seen as a form of few-shot learning. This means that you can simply provide instructions to the model, along with a few optional examples, and the model will produce the desired output quite reliably. This is different from fine-tuning, which is a transfer learning technique that can transform a pre-trained language model, such as GPT-3, into a task-specific model, as was done with ChatGPT.
Teaching a Chatbot Domain-Specific Knowledge
As an experiment, and to understand the underlying technology better, I spent a couple of weeks researching and building a chatbot which can produce answers to questions based purely on factual knowledge using a RAG architecture. This ensures the accuracy of the content produced by the chatbot by grounding it in a source of truth.
The first step in this pipeline is to collect the knowledge I want the chatbot to have. As this was a simple experiment, I did this by parsing a pdf document, extracting contextual chunks of text and linking them in a way that describes the structure of the document. That is, if one chunk of text contains a reference to another, a context link is created.
With these chunks of text extracted, I then passed each of them through one of OpenAI’s text embedding models and stored it in a vector database. These models produce embeddings, which are a numerical way of representing the semantic meaning of each chunk of text in a latent space. As can be seen in the image below, embeddings that are numerically similar are also semantically similar. For example, the embedding of “canine companions say” will be more similar to the embedding of “woof” than that of “meow.”
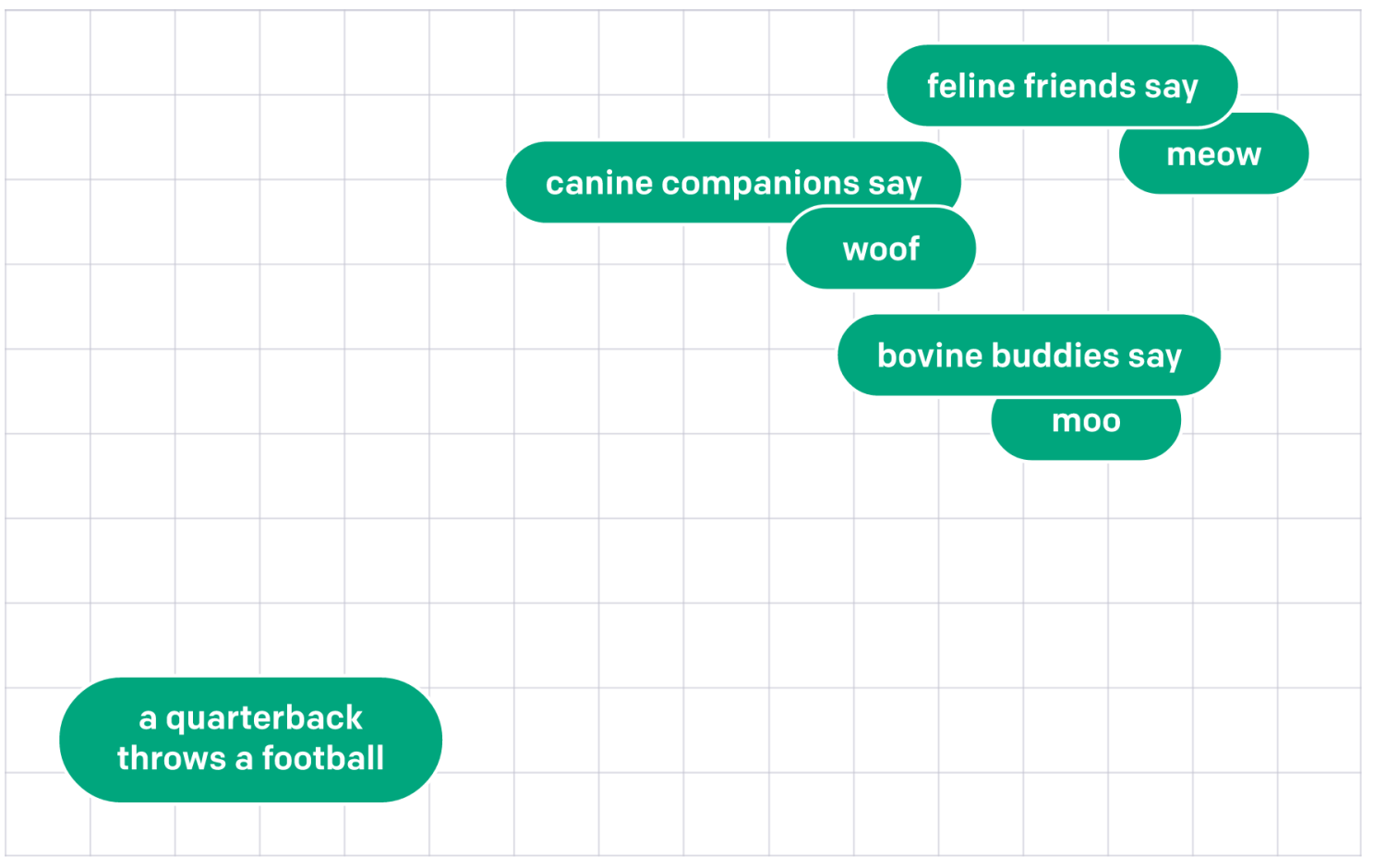
Example illustrating text embedding phrase similarity. Credit: OpenAI - openai.com/blog/introducing-text-and-code-embeddings/
In my implementation, when a user asks a question about a specific document, the program quickly queries the vector store and extracts the most semantically relevant chunks of text to the question. It also makes use of the context links created earlier to provide additional context. These are then fed into a specifically designed prompt, which instructs the foundation model to synthesize an answer to the user’s question based purely on the provided text. The following is a simplified example of one of the prompts I experimented with.
You are an agent tasked with answering questions based on a provided query.
If the query is too general, ask the user to be more specific, and provide suggestions.
Respond to the query using only the context provided.
If insufficient information is provided, do not answer the question.
Do not include irrelevant information in the answer body.
Be as concise as possible.
Query: {query}
Context: {context}
Response:
Results and Improvements
The video below shows a demo of running the program with the bitcoin whitepaper as an input. The user is able to ask questions (indicated by Query), and the chatbot responds (GPT) using only context extracted from the document. Even though this initial experiment is extremely simple, it yields impressive results.
In another test, I provided it with technical documentation from Delft Aerospace Rocket Engineering (a student rocketry society which I am a part of). This resulted in an efficient way to look up specific technical aspects of our designs, and even combine context from different documents together.
In its current form, my implementation is extremely inefficient, as it requires very large prompts to be supplied to the LLM to ensure enough context to answer questions accurately. As such, I am looking more deeply into NER (Named Entity Recognition) and RE (Relation Extraction) models to extract key facts from the text and construct a knowledge graph with information from various documents. With an appropriate querying method, this could be a good way to create “memory” for the GPT, and have it easily accessible and interlinked via a Graph-RAG approach.